FAQ
Cette FAQ technique a pour objectif de rassembler des résolutions de problèmes récurrents rencontrés lors de nos activités de développement.
Erreur de protocole TLS dans un projet Java
Problème
Lorsque l'application Java se connecte au serveur mail, une erreur de protocole lié aux TLS se produit :
No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
Solution
C'est lié à un problème de dépendances lors du build par Maven, il faut vérifier les dépendances liées aux mails dans le Maven Dependency Tree.
Exemple sur IntelliJ :
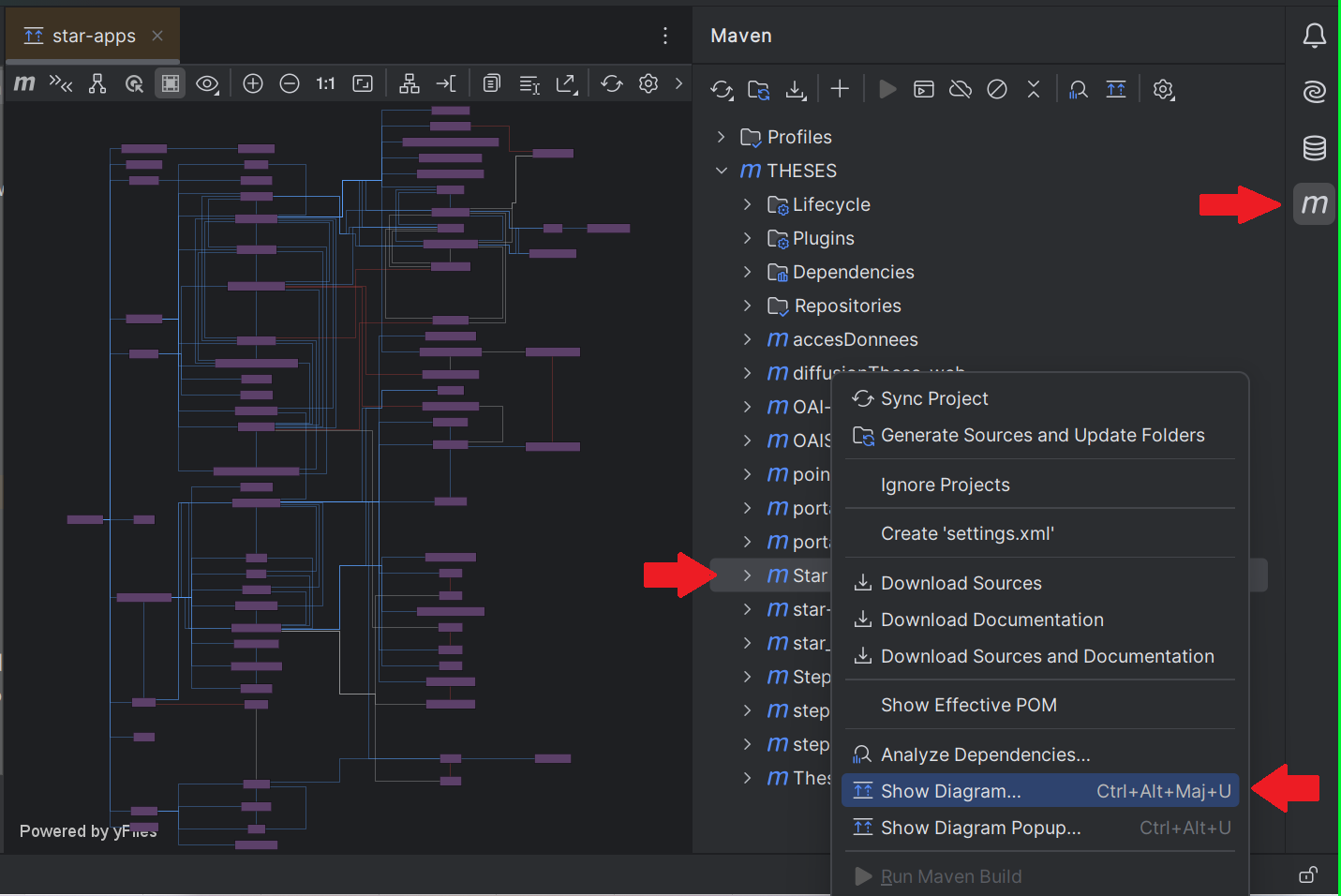 Puis une fois identifiée(s), ajouter une exclusion pour les librairies qui importent des versions de librairies mail obsolètes (qui ne supporte pas le nouveau protocole), par exemple :
Puis une fois identifiée(s), ajouter une exclusion pour les librairies qui importent des versions de librairies mail obsolètes (qui ne supporte pas le nouveau protocole), par exemple :
- mettre
<exclusion>
<groupId>javax.mail</groupId>
<artifactId>mail</artifactId>
</exclusion>
dans le pom - Attention ! Les librairies de mails peuvent avoir différents noms (mail, javax.mail, jakarta.mail...) mais peuvent tout de même entrer en collision.
Erreur 404 lors d'un déploiement de war dans un tomcat
Problème
Lorsqu'on se connecte à l'url de l'application, on obtient un message comme ci-dessous :
État HTTP 404 – Not Found
Type Rapport d'état
message /Theses-Imports-0.0.1-SNAPSHOT/
description La ressource demandée n'est pas disponible.
Apache Tomcat/9.0.12
Solution
pour les war conçu avec Spring, il faut :
- mettre
<packaging>war</packaging>dans le pom - ne pas oublier : extends SpringBootServletInitializer dans la classe principale
Versioning : supprimer les derniers commit erronés en local
Problème
J'ai commité des changements en local mais l'application ne fonctionne plus, je n'aurais pas du commiter
Solution
git reset --hard HEAD~n
avec n commits que l'on souhaite supprimer
Versioning : supprimer les derniers commit erronés push sur le dépot distant
Problème
J'ai commit puis push sur le dépôt distant des modifications que je n'aurais pas du envoyer.
Solution
git reset --hard hashDuCommitSurLequelJeVeuxRevenir
git push origin develop -f
Ici le push se fait sur le develop, mais remplacer develop par la branche sur laquelle vous voulez revenir en arrière.
Attention : les commits supprimées disparaissent de l'historique
Versioning avec Intellij : rafraichir le cache des fichiers versionnés (être sur de ce qui va partir sur le dépôt) - codes couleurs explorateur
Problème
J'ai modifié mon .gitignore, mais je ne sais pas si ce que j'ai mis dedans est bien pris en compte, intellij ne rafraichit pas la couleur de mes fichiers. Dois-je commiter avec le risque d'avoir indexé des fichiers que je souhaitais voir ignorés ?
Solution
Permet d'être sur avant un commit d'avoir dans l'onglet 1[Project] les couleurs des différents fichiers à jour en se basant sur le .gitignore
Ainsi on est sur de savoir quels fichiers seront ignorés, indexés avant tout commit, notamment sur un dépôt public.
La solution pour rafraichir le cache intellij pour le File Status Highlights de l'explorateur taper les commandes suivantes dans l'onglet terminal d'intellij ou dans un terminal à part, en se plaçant à la racine du projet
git rm -r --cached .
git add .
git commit -m 'git cache cleared'
git push
ou version rapide
git rm -r --cached . && git add . && git commit -m 'git cache cleared' && git push
Cela permet d'avoir à jour dans l'onglet Project sur tous les fichiers les couleurs à jour et d'être sur en cas d'envoi sur un dépôt public que les fichiers sensibles sont bien ignorés. Ca à l'air de marcher à tous les coups :)
- rouge -> non versionné
- bleu -> modifié
- or -> ignoré
- vert -> ajouté
Pour toutes les couleurs / status https://www.jetbrains.com/help/idea/file-status-highlights.html#views
Pour la manip https://gist.github.com/joemaffia/bacf72580d425c8eee67ec68708a4124
Pour ignorer les applications.properties correctement dans le fichier .gitignore
### Applications.properties ###
**/resources/*.properties
Versioning : supprimer ou remplacer le dernier commit
Problème
J'ai commité en local des changements que j'ai envoyé sur le depôt distant avec des erreurs. Je souhaiterais revenir en arrière.
Cas 1 : Il a été envoyé sur un autre dépôt
- revient en fait à effectuer le commit inverse de celui qu'on veut supprimer, car on ne peut pas casser l'historique des commits sur le dépôt distant.
- ce commit va supprimer les lignes qui ont été ajoutées, et remodifier les lignes qui ont été modifiées.
git revert HEAD
- Un nouveau commit sera créé, ce commit contiendra les modifications inverses de HEAD.
Cas 2 : Il n'a pas été envoyé sur un dépôt distant : modification
- il est tout à fait possible de le modifier, sans devoir passer par un commit inverse
- Il faut effectuer les modifications qui ont été oubliées, ou qui n'avaient pas lieu d'être puis commiter en utiliser l'argument --amend
git commit --amend
- Après cette commande, Git redemandera un nouveau message de commit. Rien n'empêche d'utiliser celui qui a déjà été utilisé.
Cas 2 : Il n'a pas été envoyé sur un dépôt distant : suppression
- Suppression du commit local + MAJ du répertoire de travail et l'index (on supprime tout)
git reset --hard HEAD^
- Suppression du commit local, mais conservation des changements en cours dans le repertoire de travail et l'index
git reset --mixed HEAD^
Versioning : commiter avec prise en compte du # en premier caractère
Problème
Normalement tous les commits des projets doivent avoir la syntaxe suivante
#NUMERO_TICKET_GITHUB TYPE: message_commit_en_anglais
Parfois le # n'est pas pris en compte pour remontée dans gitlab, notamment sous linux, ou bien git affiche un message d'erreur disant qu'il ne peut commiter un message commençant par un #
Solution
Commencer son message de commit avec l'option suivante
$git commit --cleanup=whitespace
Des annotations @Value renvoient null
Problème
Dans un projet Spring, des annotations @Value ne récupèrent pas les valeurs depuis les fichiers *.properties
Solution
Cette annotation ne fonctionne que pour les objets instanciés via Spring c'est-à-dire par exemple avec l'annotation @Autowired.
Un objet instancié via new ne pourra pas utiliser @Value.
Erreur "ORA-28040: No matching authentication protocol"
Problème
Lors de la migration vers Oracle 12C, on a l'erreur : ORA-28040: No matching authentication protocol
Solution
Il faut mettre à jour la dépendance jdbc, par exemple remplacer :
<dependency>
<groupId>com.oracle.jdbc</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3.0</version>
</dependency>
par :
<dependency>
<groupId>oracle.ojdbc</groupId>
<artifactId>ojdbc</artifactId>
<version>12.1.0.1.0</version>
</dependency>
Si on manipule des champs XMLTYPE, il faut ajouter les librairies xdb et xmlparser. Mais elles doivent être compatibles entre elles, par exemple :
<dependency>
<groupId>oracle.ojdbc</groupId>
<artifactId>xdb6</artifactId>
<version>11.2.0.3.0</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3</version>
</dependency>
<dependency>
<groupId>oracle.ojdbc</groupId>
<artifactId>xmlparserv2</artifactId>
<version>11.2.0.3.0</version>
<scope>runtime</scope>
</dependency>
Autre possibilité si jamais on est bloqué pour mettre à jour les librairies : utiliser la même version ojdbc6 et configurer l'authentification Oracle pour accepter des connexions de niveau 10, 11 et 12.
Erreur SAXParser.. suite à la mise à jour de la dépendance Oracle xmlparserv2 ou suite au passage à Tomcat 9
Problème
Lors de la mise à jour des dépendances Oracle, on a une erreur : SAXParser. L'erreur peut aussi arriver lorsqu'on passe une webapp de Tomcat 8 à Tomcat 9, sans forcément changer les dépendances Oracle : erreur SAXParser...
ex :
java.lang.NoClassDefFoundError: oracle/i18n/util/LocaleMapper
(cette erreur peut se produire à l'appel d'un service ou au chargement de la webapp par Tomcat).
Solution
La dépendance Oracle xmlparserv2 devient l'implémentation par défaut pour les javax.xml.parsers et javax.xml.transform
Pour re-initialiser les implémentations par défaut, il faut :
Soit mettre ce bout de code au démarrage de l'application (par exemple dans une classe implémentant ServletContextListener et la méthode contextInitialized) :
System.setProperty("javax.xml.parsers.SAXParserFactory","com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl");
System.setProperty("javax.xml.transform.TransformerFactory","com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl");
System.setProperty("javax.xml.parsers.DocumentBuilderFactory","com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl");
Soit définir ces propriétés en paramètre de la JVM :
-Djavax.xml.parsers.DocumentBuilderFactory=com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl
-Djavax.xml.transform.TransformerFactory=com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl
-Djavax.xml.parsers.SAXParserFactory=com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl
Erreur : SQLException: Validation (commit) impossible lorsque le mode autocommit est activé
Problème
Ou :
java.sql.SQLException: Could not commit with auto-commit set on
Cette erreur peut survenir suite à la mise à jour de la dépendance ojdbc.jar lors de la migration vers une version plus récente d'Oracle (12c en l'occurrence).
Solution
il faut ajouter cette option lors du démarrage de la JVM (par exemple dans JAVA_OPTS du bin/catalina.sh de Tomcat) :
-Doracle.jdbc.autoCommitSpecCompliant=false
Oracle SQL Developer : Multiple table view
Problème
Oracle SQL ne permet pas de base les onglets multiples pour gérer les tables.
Solution
https://stackoverflow.com/questions/1912129/oracle-sql-developer-multiple-table-views Outils > Preferences > Bases de donnees > Visualiseur d'objets
VueJS : Force resolution of vulnerabilities
Problème
Sous vuejs ou autre projet utilisant npm, lors du lancement de l'application avec npm run serve, ou lors de l'installation d'un nouveau module avec npm install, des vulnerabilités dans les modules peuvent apparaitre.
- la commande npm audit permet de les investiguer.
- la commande nom audit fix --force ne permet souvent pas de les fixer. Cela est du au fait que cette commande n'agit que sur les versions des modules, et non les versions des sous-modules empaquetés par certains modules. Il faut alors paramétrer les versions des sous-modules dans le package.json de l'application, puis lancer un script spécifique, après chaque npm install, afin de rétablir les version qui évitent ces vulnérabilités.
Solution
install in package.json file
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"test:unit": "vue-cli-service test:unit",
"lint": "vue-cli-service lint",
"preinstall": "npx npm-force-resolutions"
},
"resolutions": {
"yargs-parser": "15.0.1"
},
As the example, the script preinstall was added, and a specific version of yargs-parser (who depends on top level jest npm module) will be forced to update in node_module. Then, run the script: npx npm-force-resolutions and just tap on commands:
npm i && npm audit fix --force
Tip: think to run the script after each npm installation modules.
Après cela, les vulnérabilités doivent avoir disparues.
Oracle SQL Developer : optimisation de requêtes
Problème
Parfois une requête peut être très lente.
Solution
Dans sql developer, après s'être connecté à une instance de base de données, taper la requête, faire ctrl+f12 (ou cliquer sur la cinquième icone (à côté de "commit")). Ensuite dans l'onglet "détail", nous avons les plans d'éxecutions, les indexes à créer, les reformulations de requêtes éventuelles...il suffit de suivre les indications.
VueJS : Cannot find module : problème de librairie
Problème
TS2307: Cannot find module... alors que le module à bien été installé Note: npm i -g installe globalement les modules
Solution
Il ne faut pas intégrer le repertoire node_modules globalement dans le tsconfig.json. Regarder dans l'IDE quelle librairie est manquante. Modifier le fichier tsconfig.json comme suit :
"include": [
"src/**/*.ts",
"src/**/*.tsx",
"src/**/*.vue",
"tests/**/*.ts",
"tests/**/*.tsx",
"node_modules/[NOM_LIBRAIRIE_A_INTEGRER]"
],
En dernier recours
Supprimer le fichier tsconfig.json à la racine du projet Faire
npx tsc --init
pour le recréer. Les imports doivent désormais fonctionner.
VueJS : Travailler avec des fichiers JSON stockés dans le projet pour simuler des retours WS du back-end
Problème
Pour des raisons diverses, certains ws peuvent être anormalement long en termes de temps de réponse pour fournir leur retour, sous forme de Json ou xml. Stocker le retour d'un ws en local sous forme d'un fichier json permet de travailler beaucoup plus rapidement dans un environnement isolé et non dépendant pour le developpement front.
Solution
A partir de Typescript 2.9 Exemple de fichier JSON placé dans le projet
{
"primaryBright": "#2DC6FB",
"primaryMain": "#05B4F0",
"primaryDarker": "#04A1D7",
"primaryDarkest": "#048FBE",
"secondaryBright": "#4CD2C0",
"secondaryMain": "#00BFA5",
"secondaryDarker": "#009884",
"secondaryDarkest": "#007F6E",
"tertiaryMain": "#FA555A",
"tertiaryDarker": "#F93C42",
"tertiaryDarkest": "#F9232A",
"darkGrey": "#333333",
"lightGrey": "#777777"
}
Le fichier ts ou l'on veut utiliser le json
import colorsJson from '../colors.json'; // This import style requires "esModuleInterop", see "side notes"
console.log(colorsJson.primaryBright);
Le fichier tsconfig.json doit contenir dans la rubrique compilerOptions
"resolveJsonModule": true,
"esModuleInterop": true,
Source : Stackoverflow : importing-json-file-in-typescript
Remplacer le mot de passe de l'utilitaire git sur Windows
Problème
A partir du 13 aout 2021, l'authentification par mot de passe ne fonctionnera plus sur Github. On veut remplacer son mot de passe dès maintenant.
Solution
-
se connecter sur son compte Github, dans "Settings", dans "Developer settings", dans "Personal access tokens", il faut créer un token
-
dans le panneau de contrôle de Windows, dans "comptes utilisateurs", dans "gérer vos informations d'identification", dans "informations d'identification Windows", dans "informations d'identification génériques", on clique sur la clé : "git:https://github.com" et en cliquant "modifier", on peut remplacer le mot de passe par le token créé préalablement sur Github.
Harmoniser la configuration des fichiers .prettierrc.yaml, .eslintrc.js, tsconfig.json dans une architecture front, désactiver certaines règles eslint par rapport a un projet mixant typescript et javascript
Problème
La configuration des fichiers mentionnés ci-dessus doit respecter une inter-compatibilité entre eux afin d'éviter des erreurs consoles ou des signalement de l'IDE.
Les projets en ts vont parfois utiliser des librairies ou des portions de code historiquement construite en js. Le typage n'est alors pas le même, la syntaxe peut changer.
Comment configurer eslint pour le mettre en accord avec ts config et les règles de prettier ?
Voici un tableau de compatibilite

Solution
- Désactiver certaines règles eslint en regardant sur la documentation officielle dans le fichier .eslintrc.js (sur chaque règle il y a une rubrique expliquant comment désactiver la règle à travers le fichier .eslintrc.js https://github.com/typescript-eslint/typescript-eslint/blob/master/packages/eslint-plugin/docs/rules/explicit-function-return-type.md
- Configurer les fichiers en respectant le tableau de compatibilité.
- Configurer prettierrc avec trailingComma pas en es5
- Règler la conf
Erreur lors de la création d'une release avec Jenkins et OpenJDK 11
Problème
Lorsqu'on veut réaliser une release, elle ne fonctionne pas : car il y a des ERROR dans la génération de la javadoc :
[INFO] [ERROR] Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:3.3.0:jar (attach-javadocs) on project autorites: MavenReportException: Error while generating Javadoc:
Solution
Il faut indiquer au plugin maven-javadoc qu'on souhaite un niveau WARN à la place de ERROR, afin que la release puisse se faire :
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<release.javadoc.root.path>javadocAPPLI/</release.javadoc.root.path>
<additionalparam>-Xdoclint:none</additionalparam>
<doclint>none</doclint>
</properties>
et
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<executions>
<execution>
<id>attach-javadocs</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
<configuration>
<additionalOptions>
<additionalOption>-Xdoclint:none</additionalOption>
</additionalOptions>
<failOnError>false</failOnError>
</configuration>
</plugin>
Jenkins : générer du code dans les Jenkinsfile
Problème
On veut réaliser certaines actions dans un Jenkinsfile.
Solution
Jenkins met à disposition un générateur de code "Snippet Generator" accessible depuis les jobs de type "multibranch pipeline". Dans le menu de gauche du job, il faut cliquer sur "Pipeline Syntax". On accède alors à un formulaire pour choisir l'action à réaliser (checkout de code, publier via ssh etc.) et on peut générer le code à copier dans le jenkinsfile pour notre job.
Maven Plugin not found in IntelliJ IDE
Problème
Régulièrement dans les pom.xml le plugin suivant pose problème.
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
Plugin 'org.springframework.boot:spring-boot-maven-plugin:' not found
Solution
Dans les préférences d'Intelli J, naviguez jusqu'à "Build, Execution, Deployment > Build Tools > Maven", cochez "Use plugin registry", et cliquez sur "OK". Puis "File > Invalidate Caches / Restart" pour recharger Intelli J. L'erreur disparaîtra automatiquement.
Problème d'injection d'un mock dans les tests unitaires
Problème
Dans un test unitaire il arrive que, lors de la création d'un mock, l'objet ne soit pas injecté correctement dans la classe et qu'on ait une NullPointerException sur l'objet (par exemple, on mock une classe de la couche service qui est injectée dans un controller).
Solution
Le problème peut venir de la façon dont les injections de dépendances sont déclarées. Si les objets sont injectés via une annotation @Autowired, cela peut créer le problème. Pour le corriger, il suffit de supprimer l'annotation @Autowired, de passer le champ en final, et de l'initialiser dans le constructeur de la classe (en passant l'objet en paramètre).
Exemple :
private EtablissementService service;
devient :
private final EtablissementService service;
public MaClasse(EtablissementService service) {
this.service = service;
}
Faille de sécurité log4shell et applications Java
Problème
On veut mettre à jour log4j dans les application java qui utilisent des vielles versions. La version préconisée de log4j qui corrige log4shell est la version 2.17.1
Solution
Application Java utilisant slf4j-log4j12
Si l'appli java dépend de slf4j-log4j12 alors voici comment procéder. Le principe sera de modifier un minimum de code en utilisant la librairie log4j-1.2-api qui permet de conserver l'ancienne interface java de log4j v1 tout en utilisant la nouvelle version de log4j v2.17.1. Une subtilité est d'empêcher slf4j-log4j12 d'utiliser log4j v1 en utilisant le système d'<exclusion>.
- Dans pom.xml placer ces dépendances :
<!-- Utilisation de log4j 2.17.1 qui corrige la faille log4shell -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.17.1</version>
</dependency>
<!-- Wrapper qui permet de faire en sorte que le code qui appelle
l'API de log4j v1.2 fonctionne et log dans une version log4j v2.17.1
(qui elle corrige la faille log4shell)
-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>2.17.1</version>
</dependency>
<!-- C'est slf4j-log4j12 qui est utilisé dans le code de Rafa -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.32</version>
<!-- exclusion de log4j pour que slf4j-log4j12 utilise
log4j-1.2-api (cf plus haut) qui lui même utilise
log4j-core dans sa version 2.17.1 (qui corrige la faille log4shell) -->
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
- Dans le répertoire
src/main/resources, remplacer le fichier de paramétrage log4j.properties par log4j2.xml dont voici un exemple de contenu :
<Configuration>
<Appenders>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern="%style{%d{ISO8601}}{black} %highlight{%-5level }[%style{%t}{bright,blue}] %style{%C{1.}}{dark,yellow}: %msg%n%throwable" />
</Console>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</Configuration>
- Recompiler et redéployer l'application en veillant à la tester dans les grandes lignes.
Monitoring des conteneurs docker
Problème
J'aimerais connaitre la consommation CPU et RAM de mon/mes conteneurs sur un serveur.
Solution
Utiliser l'outil ctop en tapant ceci en ligne de commande sur le serveur :
sudo docker run --rm -ti --volume /var/run/docker.sock:/var/run/docker.sock:ro quay.io/vektorlab/ctop:latest
Vous obtiendrez une visualisation qui ressemblera à ceci :

Docker : Erreur connexion Oracle ORA-01882: timezone region not found
Problème
Depuis les conteneurs dockers sur diplotaxis, l'application n'arrive pas à se connecter à la base de données Oracle et renvoie l'erreur ORA-01882: timezone region not found.
Solution
Cela vient d'une différence de timezone entre la JVM (et donc le driver ojdbc) et la base de données.
Il faut ajouter en option en conteneur, dans la partie environnement du docker compose, le paramètre suivant :
JAVA_OPTS: "-Doracle.jdbc.timezoneAsRegion=false -Duser.timezone=CEST"
Exemples : https://github.com/abes-esr/qualinka-microservices/blob/20cc3986ae2ae7a9dad1412efc26c1dad421a279/docker-compose.yaml#L154 ou https://git.abes.fr/depots/ansible-nbt/-/blob/master/ln-docker/templates/ln_docker-compose.j2
Solution alternative
Si la solution au dessus ne fonctionne pas, il est également possible de paramétrer la timezone directement dans le code Java. Il faut ajouter le code suivant :
TimeZone timeZone = TimeZone.getTimeZone("Europe/Paris");
TimeZone.setDefault(timeZone);
avant la connexion ou l'execution de la première requête SQL.
Configuration d'un environnement Docker sous Windows 10
Installation de WSL et d'une distribution Linux
source : docs.microsoft.com
Installation et activation de WSL2
-
vérifier si WSL est installé :
wsl -l -v -
pour être certain de disposer de la dernière version (WSL2) ou pour installer WSL2 depuis zéro, voici la commande à taper dans un PowerShell en mode administrateur :
wsl –-install
Installation d'une distribution Linux (Ubuntu pour l'exemple) dans WSL
Par défaut, l'installation de WSL 2 installera également une distribution Linux (Ubuntu). Néanmoins, si tel n'est pas le cas, suivre le protocole ci-dessous.
-
vérifier si une distribution Linux est déjà installée dans WSL
wsl -l -v
-
Si une distribution Linux est listée en version 1, saisissez
wsl -–set-version <nom_de_la_distribution> 2 -
si aucune distribution n'est installée, saisir
wsl –-install -d <nom_de_la_distribution>
Passer la distribution de Linux installée dans WSL par défaut :
-
PowerShell en mode administrateur
wsl --set-default <nom_de_la_distribution>
Installation de Docker Desktop
-
Télécharger et installer docker desktop avec l’option d’installation de WSL2 (cocher la case « Enable Hyper-V Windows Features » durant l'installation) : www.docker.com
-
Une fois l'installation terminée, ouvrir Docker et aller dans les Settings/Resources/WSL Integration pour cocher les cases
[x] Enable integration with my default WSL distro »[x] <nom_de_la_distribution_Linux>
Création d'un user individuel dans la distribution Linux WSL2
-
Ouvrir PowerShell ou une invite de commande
-
entrer dans la machine virtuelle :
wsl -
ajouter un utilisateur Linux (indiquer son login individuel habituel) :
adduser <nom_de_l'utilisateur> -
donner les droits sudo à l'utilisateur
usermod –aG sudo <nom_de_l'utilateur> -
donner les droits Docker à l'utilisateur
usermod –aG docker <nom_de_l'utilateur> -
sortir de la machine virtuelle
exit -
changer l'utilisateur par défaut qui sera utilisé au moment de démarrer la distribution Linux WSL2
ubuntu config --default-user <nom_de_l'utilateur>
Vérification du fonctionnement de Docker
-
Ouvrir PowerShell ou une invite de commande
-
Entrer dans la machine virtuelle :
wsl -
Afficher la version de Docker :
docker -v -
Afficher la version de Docker-Compose :
docker-compose -v -
Télécharger et démarrer le conteneur docker d'essai hello-world :
docker run --rm hello-worldLe message « Hello from Docker !» s'affiche dans la console
Installer et paramétrer Git
-
Ouvrir PowerShell ou une invite de commande
-
Entrer dans la machine virtuelle :
wsl -
installer Git :
sudo apt install git -
créer un jeu de clefs SSH privée/publique en suivant les recommandations du document suivant (chapitre "Générer des clés avec ssh-keygen") : docs.microsoft.com
-
enregistrer la clef publique sur son compte GitHub :
- ouvrir les "Settings" de son compte GitHub et aller dans la rubrique "SSH and GPG keys" ici : https://github.com/settings/keys
- cliquer sur le bouton "New SSH key"
- donner un nom à la nouvelle clef SSH dans le champ "Title"
- coller l'intégralité de la clef publique dans le champ "Key"
-
dans WSL, en 'user' saisir :
cdPuis saisir :
explorer.exe .Cela ouvre une nouvelle fenêtre Windows qui affiche le répertoire racine de la machine virtuelle en cours. Ouvrir le répertoire .ssh
\\wsl$\<nom_de_la_distribution_linux>\home\<nom_de_l'utilisateur_défini_dans_wsl>\.ssh -
Dans cette nouvelle fenêtre, coller la paire de clefs privée/publique que vous trouverez dans le répertoire .ssh de votre session utilisateur Windows
C:\Users\<votre_nom_d'utilisateur>\.ssh
Préparation du répertoire de travail
-
Ouvrir PowerShell ou une invite de commande
-
Entrer dans la machine virtuelle :
wsl -
créer le répertoire pod :
sudo mkdir /opt/pod/ -
donner les droits de lecture/écriture à tous au répertoire pod :
sudo chmod a+wrx /opt/pod -
entrer dans le répertoire pod :
cd /opt/pod
Exemple d'utilisation du répertoire /opt/pod avec Qualimarc
-
Cloner le projet à partir de GitHub. Dans wsl, saisir :
cd /opt/pod/puis
git clone git@github.com:abes-esr/qualimarc-docker.git -
Pour la suite, se référer au ReadMe Qualimarc-Docker https://github.com/abes-esr/qualimarc-docker.git
Erreur envoi de mail : "PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target"
Problème
Lors d'une tentative d'envoi de mail dans une application web, on rencontre l'erreur :
nested exception is:
javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
Solution
Il faut spécifier où trouver le certificat lors du lancement du Tomcat. Pour celà, on ajoute dans JAVA_OPTS du catalina.sh le chemin vers le certificat, exemple :
JAVA_OPTS="$JAVA_OPTS -Djavax.net.ssl.trustStore=/home/tomcat/theses/jssecacerts [...]
Secret envoyé par erreur sur GitHub
Problème
J'ai envoyé par erreur un mot de passe sensible dans un commit/push, que faire ?
Solution
Suivre les préconisation de Github décrites ici : https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/removing-sensitive-data-from-a-repository
En particulier l'outil BFG est cité qui a le mérite d'être facile à utiliser.
Une fois le nettoyage réalisé, il est probable que votre commit soit toujours présent sur le web (cf section dans la doc de github). Le message suivant s'affiche alors et signifie que le commit existe mais n'est plus racroché à un commit :
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Pour le nettoyer, il faut alors demander au support github de lancer un garbage collector sur le dépôt github pour que le commit soit complètement nettoyé. Lien direct vers le formulaire.
A noter : en fonction de la criticité du mot de passe, penser à révoquer le mot de passe en modifiant sa valeur sur les environnements de dev, test, et prod.
Erreur Désérialisation JSON vers Java
Problème
On veut désérialiser une réponse json d'Elastic Search vers des classes modèles Java. On a l'erreur :
Error during generated code invocation com.intellij.debugger.engine.evaluation.EvaluateException: Method threw 'co.elastic.clients.json.JsonpMappingException' exception
Solution
Jackson utilise le constructeur par défaut des classes modèles. Si aucun constructeur n'est présent dans la classe modèle, Jackson le génère. Par contre, l'erreur se produit si un constructeur qui n'itialise pas tous les champs est présent dans la classe modèle.
Dans ce cas, il faut ajouter le constructeur par défaut.
Erreur version conflict, document already exists (current version [1])
Problème
Notre batch envoie des requêtes DELETE puis POST avec le même identifiant et rapidement on a l'erreur "version conflict".
Solution
A chaque requête, on force ES à rafraichir l'index pour qu'il rende visible immédiatement le résultat de la requête. Exemple en utilisant l'API Java pour une requête de suppression :
DeleteRequest.Builder builder = new DeleteRequest.Builder();
builder.refresh(Refresh.True);
builder.build()
Erreur java.lang.IllegalStateException: More than the maximum allowed number of headers, [100], were detected.
Problème
Tomcat est configuré par défaut pour ne pas recevoir plus de 100 headers HTTP. Mais dans le cadre de la fédération d'identité RENATER, les attributs renvoyés font excéder cette limite (cf. https://services.renater.fr/federation/documentation/fiches-techniques/sp/config-sp-mdattributeextractor). La solution qui consiste à positionner la variable server.max-http--header-size dans l'application properties ne fonctionne pas pour nous (il s'agit de la taille et non du nombre de headers).
Solution
Il faut ajouter une classe de configuration pour le tomcat embarqué comme présenté ici : https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#web.servlet.embedded-container.customizing.programmatic)
exemple :
package fr.abes.theses.diffusion.utils;
import org.apache.coyote.ProtocolHandler;
import org.apache.coyote.http11.AbstractHttp11Protocol;
import org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory;
import org.springframework.boot.web.server.WebServerFactoryCustomizer;
import org.springframework.stereotype.Component;
@Component
public class TomcatCustomizer implements WebServerFactoryCustomizer<TomcatServletWebServerFactory> {
@Override
public void customize(TomcatServletWebServerFactory server) {
server.addConnectorCustomizers((connector) -> {
ProtocolHandler handler = connector.getProtocolHandler();
AbstractHttp11Protocol protocol = (AbstractHttp11Protocol) handler;
protocol.setMaxHeaderCount(500);
});
}
}
Comment accéder à une variable dépendante de l'environnement depuis log4j2.xml
Problème
Dans la configuration log4j2, on peut vouloir créer une propriété dont la valeur est dépendante de l'environnement d'exécution de l'application (dev / test / prod). On pourrait être tenté d'aller chercher la variable dans le application.properties du dit environnement, mais cette approche ne fonctionne pas. En effet, lorsque l'application se lance, log4j est initialisé avant Spring (pour pouvoir afficher la trace d'exécution du lancement de spring), et ne connait donc pas le SPRING_PROFILES_ACTIVE définit par Spring.
Solution
Utiliser une variable d'environnement pour alimenter la variable. Par exemple :
<Property name="kafkaServer">${env:SPRING_KAFKA_PRODUCER_BOOTSTRAP_SERVERS}</Property>
Il suffit ensuite de d�éclarer la variable SPRING_KAFKA_PRODUCER_BOOTSTRAP_SERVERS dans le docker-compose de l'application dans la section environment
bacon2kafka-api:
image: abesesr/convergence:${BACON2KAFKA_API_VERSION}
container_name: bacon2kafka-api
restart: unless-stopped
mem_limit: ${MEM_LIMIT}
environment:
SPRING_PROFILES_ACTIVE: dev
SPRING_KAFKA_PRODUCER_BOOTSTRAP_SERVERS: http://somekafkaserver.com:9094
La variable peut être mise dans le .env comme toute autre variable d'environnement. Au déploiements, docker-compose va créer la variable d'environnement SPRING_KAFKA_PRODUCER_BOOTSTRAP_SERVERS et log4j peut y avoir accès directement avec l'instruction env.
Blocage dans l'exécution d'une requête d'un reader Spring Batch
Problème
Lors d'un lancement d'un batch Spring Batch, lorsque le Reader essaie d'exécuter une requête pour selectionner les lignes à traiter dans la base de données, l'erreur suivante survient :
SQL state [99999]; error code [17041]; Paramètre IN ou OUT absent dans l'index :: 1; nested exception is java.sql.SQLException: Paramètre IN ou OUT absent dans l'index :: 1
Solution
Il peut s'agir d'une exécution précédente du batch qui a laissé un état failed stocké dans les tables de Spring batch, on peut alors les nettoyer :
delete from batch_step_execution_context;
delete from batch_job_execution_params;
delete from batch_step_execution;
delete from batch_job_execution_context;
delete from batch_job_execution;
delete from batch_job_instance;
commit;
Erreur de déploiement automatique avec watchtower : "you have reached your pull rate limit"
Problème
L'outil watchtower utilisé pour le déploiement continue des applications docker Abes fait appels récurrents à l'API de dockerhub et cela peut provoquer des erreurs de ce type :
Error response from daemon: toomanyrequests you have reached your pull rate limit
Solution
Deux solutions :
- Soit souscrire au programme DockerHub OpenSource Program sur l'organisation DockerHub en question (A la date du 12/2023, c'est le cas sur l'organisation abesesr mais pas le cas sur l'organisation transitionbibliographique). Cf la limitation que permet de lever le programme OpenSource de Dockerhub :
Rate-limit removal for all users pulling public images from your project namespace
- Soit configurer watchtower pour utiliser un login/mdp dockerhub pour faire les appels à l'API de dockerhub (la limitation "rate limit" est alors moins drastique qu'un appel anonyme à l'API), voici les paramètres watchtower à utiliser dans cet exemple ici. Le login ayant des droits en lecture qui est à utiliser pour faire des docker pull sur l'organisation abesesr de dockerhub est le suivant :
dockerhubabes(le mot de passe est à demander à pic@abes.fr)
Notification slack des déploiements réalisés avec watchtower
Problème
Je souhaite que watchtower notifie un canal slack lorsqu'il déploie une nouvelle version de mon application. Pour cela je dois renseigner la variable WATCHTOWER_NOTIFICATION_SLACK_HOOK_URL au niveau du conteneur watchtower associé aux conteneurs de mon application mais je ne sais pas comment générer cette URL ?
Voici ce que j'aimerais obtenir sur slack lorsqu'une nouvelle version de mon application est déployée:
Solution
Etape 1 : vous devez vous connecter à votre espace slack.
Etape 2 : vous devez créer un canal en respectant cette nomenclature #notif-<nomappli> qui sera la cible des notifications (exemple de nom : #notif-qualimarc)
Etape 3 : vous devez vous rendre ici https://abes-esr.slack.com/apps/manage/custom-integrations puis cliquer sur "Webhooks entrants" :
Etape 4 : vous devez ensuite créer un nouveau webhook entrant en cliquant ici :
Etape 5 : choisissez sur quel canal vous souhaitez envoyer vos notifications puis créer votre webhook :
Etape 6 : sur l'écran suivant vous obtenez l'URL que vous pouvez copier coller pour la reporter dans la valeur de la variable WATCHTOWER_NOTIFICATION_SLACK_HOOK_URL :
Dans cette étape 6 vous pouvez si vous le souhaitez configurer le nom du bot, son logo etc pour améliorer l'apparence sur slack mais ce n'est pas obligatoire.
Accès impossible sur un volume docker depuis le serveur hote
Problème
Parfois nous devons accéder depuis le serveur hote à un volume d'un conteneur docker déporté sur le disque du serveur hote. Par exemple lorsque l'on souhaite restaurer les données d'une database à partir d'un dump sql issu des sauvegardes.
Nous avons par exemple la configuration suivante :
- répertoire sur le serveur hote :
/opt/pod/item-docker/volumes/item-db/dump/ - volume du conteneur docker monté sur ce répertoire et ayant comme cible interne au conteneur :
/backup/(le conteneur en question a comme nomitem-db-dumper) - le répertoire
/opt/pod/item-docker/volumes/item-db/dump/peut avoir des user/group ou droits d'accès en lecture/écriture qui rendent impossible son accès sans passer root.
Nous souhaiterions venir déposer le fichier pgsql_item_item-db_20220801-143201.sql.gz dans ce répertoire mais nous sommes bloqué.
Solution
La solution lourde est de solliciter un administrateur système et réseau ayant les droits root pour faire ce dépôt de fichier.
Une autre solution est de passer par la commande docker cp qui permet de copier un fichier présent sur le système hote vers un répertoire interne au conteneur ce qui a l'avantage de réutiliser les mêmes droits (user/group) du conteneur lui même et donc de ne pas être bloqué.
Voici en pratique comment procéder sur l'exemple ci-dessus :
- déposer le fichier
pgsql_item_item-db_20220801-143201.sql.gzà la racine dans /opt/pod/item-docker/ sur le serveur hôte - lancer la commande suivante :
cd /opt/pod/item-docker/
docker cp ./pgsql_item_item-db_20220801-143201.sql.gz item-db-dumper:/backup/
Votre fichier pgsql_item_item-db_20220801-143201.sql.gz sera alors déposé dans le répertoire /backup/ du conteneur qui équivaut au répertoire /opt/pod/item-docker/volumes/item-db/dump/ sur le système hôte.
Erreur lors d'un cast vers OracleResultSet
Problème
L'erreur suivante survient lors d'un Cast d'un ResultSet Hikari vers un OracleResultSet (qui permet par exemple d'utiliser getOpaque (qui permet de récupérer le contenu d'une colonne XMLType)) : java.lang.ClassCastException: class com.zaxxer.hikari.pool.HikariProxyResultSet cannot be cast to class oracle.jdbc.OracleResultSet (com.zaxxer.hikari.pool.HikariProxyResultSet and oracle.jdbc.OracleResultSet are in unnamed module of loader 'app')
Solution
Il faut définir une OracleDataSource spécifique via un Bean dans une classe @Configuration, par exemple :
@Bean
@Primary
@ConfigurationProperties("spring.db.datasource")
public DataSource dataSourceLecture() {
return DataSourceBuilder.create().url(dataSourceProperties().getUrl())
.username(dataSourceProperties().getUsername()).password(dataSourceProperties().getPassword())
.type(OracleDataSource.class).build();
}